IA et matching produit : une productivité multipliée par 20 avec Mercio
Le matching de produits, ou chaînage, consiste à relier des articles distincts mais comparables pour le consommateur. Avec la diversification des catalogues (MDD, exclusivité), ce processus est devenu chronophage et extrêmement fastidieux. Il est pourtant indispensable pour analyser la concurrence et ajuster les prix. L’analyse sémantique et l’IA permettent d’automatiser cette tâche, tout en laissant à l’humain la gestion des cas spécifiques. Une approche combinée permet ainsi d’assurer un matching précis, essentiel pour piloter efficacement le pricing et l’image-prix. Nous vous proposons, dans cet article, un retour d’expérience sur nos derniers développements.
Qu’est-ce que le matching produit pour un distributeur ?
Rapprocher des produits distincts que le consommateur considère équivalents
Le matching de produits, parfois également appelé chaînage horizontal ou plus simplement chaînage, consiste à rapprocher deux produits distincts – c’est-à-dire, aux GENCODE différents – mais comparables pour le client final.
En effet, alors que certains produits sont vendus dans différentes enseignes d’un même marché (ex : bouteille de Coca-Cola ou pot de Nutella), d’autres ne se trouvent que dans les rayons d’une seule enseigne.
Cela correspond non-seulement aux produits de marque distributeurs spécifiques à chaque enseigne, mais également aux produits de marques nationales pour lesquelles des exclusivités ont été négociées avec les industriels (nouveautés, formats spéciaux).
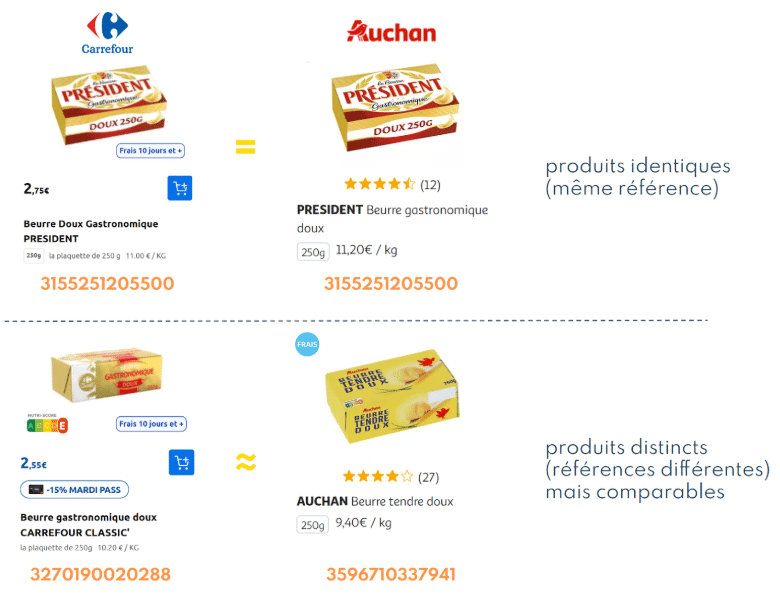
Exemples de produits strictement identiques ou simplement similaires, qui seront comparés par les clients.
L’enjeu financier est important : la part de produits qui ne sont pas strictement identiques avec le reste du marché varie en fonction des marchés et des enseignes mais représente systématiquement une part significative du CA – et encore plus de la marge – du retailer.
La dynamique est au développement de ces spécificités par enseigne, en particulier avec les objectifs de développement de la MDD annoncés par de nombreuses enseignes (Intermarché et Carrefour ciblent 40% de parts de marché sur les MDD à fin 2026 lien 1 et lien 2), une complexification de la comparabilité entre enseignes permettant plus de latitude dans la fixation des prix et le pilotage de son image prix. Cette non-comparabilité permet également de complexifier un éventuel alignement des concurrents en termes de prix. Par exemple Leroy Merlin, leader du marché du bricolage en France, n’affiche pas les EAN des produits sur son site web ce qui rend difficile tout positionnement prix relatif.
On a vu ces dernières années se jouer une grande partie de cache-cache entre enseignes, à coups de reset EAN et de sorties d’exclusivité. L’enjeu : offrir des prix attractifs visibles des consommateurs mais peu repérables par les concurrents, et ainsi, les semer dans la course au prix bas.
Une base exhaustive et fiable de liens avec le marché est utile à plusieurs titres
Pour la gestion de l’assortiment, cette base permet d’identifier les “trous” dans votre catalogue produit ou celui de vos concurrents, pour le développement ou la rationalisation de votre catalogue.
Pour le pricing, elle permet le positionnement prix de vos produits et le suivi de votre positionnement prix (calcul de vos indices prix) car les clients, eux, comparent ces produits qui répondent à un même besoin.
Sans lien de matching, vous pilotez votre pricing à l’aveugle sur un part significative de votre chiffre d’affaires.
Une liste complète et à jour de liens de matching est donc un incontournable pour le pricing d’un distributeur !
Configurer et maintenir une base de liens de matching : plus facile à dire qu’à faire !
La charge de travail pour les pricers ou chefs de produits est colossale
Un des obstacles à la fiabilisation du matching produit est la charge de travail associée au matching. Une enseigne nationale dans l’alimentaire possède entre 8.000 et 10.000 références MDD actives en moyenne, à matcher à 7 autres enseignes. C’est donc une base de plus de 50.000 liens à maintenir, à minima. Ce chiffre est une hypothèse basse, car aux MDD s’ajoutent les exclusivités, certains secteurs affichent des catalogues encore plus larges (par exemple, le bricolage) et de nouvelles références apparaissent régulièrement (nouveautés, reset EAN…).
Un processus de matching sans automatisation entraîne une charge de travail trop importante, même pour les plus grandes équipes. D’autant que le matching n’est qu’une responsabilité parmi d’autres, quelle que soit l’équipe en charge.
L’hétérogénéité des produits et une qualité des données parfois médiocre compliquent la tâche
La grande diversité des produits dans un catalogue de distributeur ajoute une autre complexité dans le travail de matching. Certaines caractéristiques seront capitales dans la valeur perçue pour le consommateur dans une unité de besoin, mais n’existeront pas pour un autre type de produits.
Par exemple, l’absence de nitrite est discriminante pour le consommateur dans le choix des jambons, alors que le parfum est important pour des produits comme les yaourts et le temps de cuisson pour les pâtes. Les caractéristiques varient donc d’une famille de produit à l’autre, et les valeurs ne sont pas normalisées.
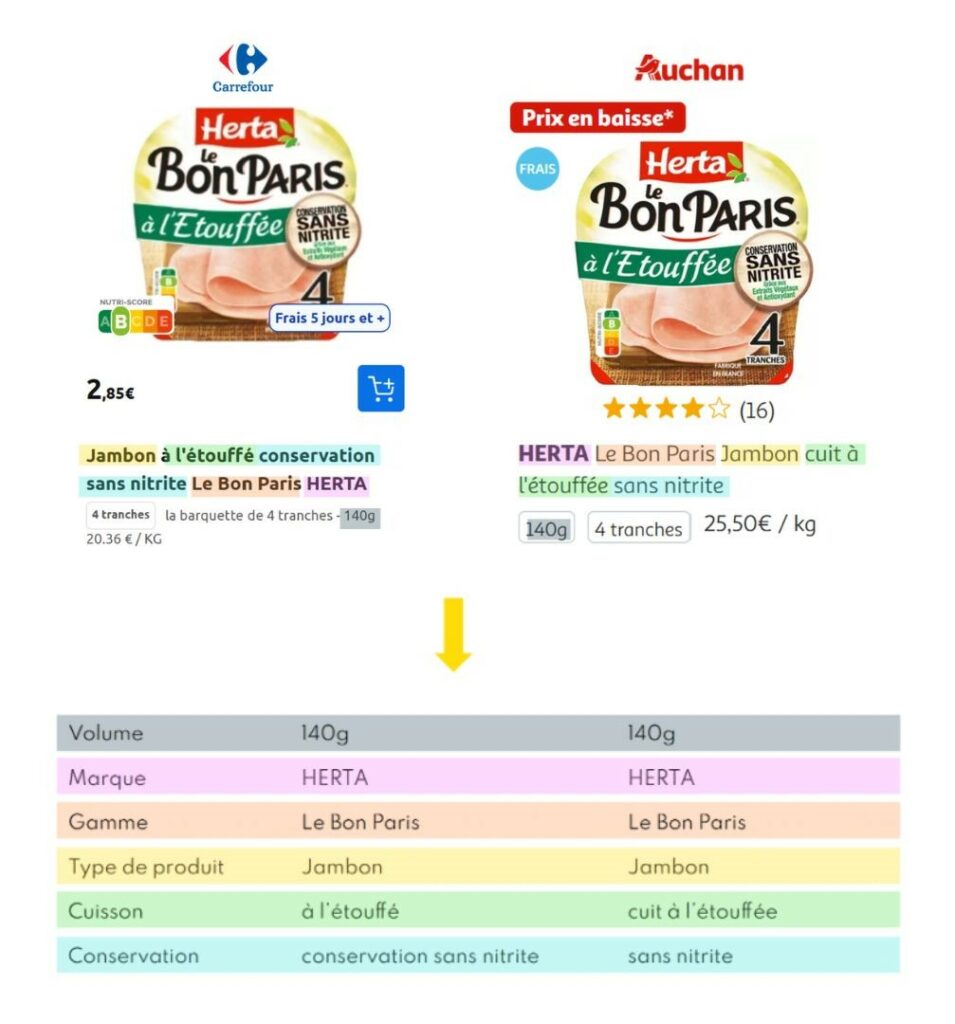
Des caractéristiques différentes selon le type de produit et non normalisées dans les catalogues
Une base de données exhaustive et structurée des caractéristiques produit n’est pas disponible, et demanderait un travail de curation sur l’ensemble des produits disponibles sur le marché (MDD et exclusivité inclus, pour le matching).
L’analyse sémantique : une application éprouvée de l’IA
Le prolongement lexical a fait l’objet de développement spectaculaires ces dernières années
Les premiers travaux de recherche pour appréhender mathématiquement la complexité du langage remontent aux années 50 mais les évolutions technologiques – en particulier l’augmentation des capacités de calcul et de stockage – et algorithmiques ont permis des progrès significatifs ces dernières années.
Le plongement lexical (word embeddings en anglais) consiste à encoder une information discrète (un mot ou un ensemble de mots) en un vecteur de chiffres dans un espace avec de nombreuses dimensions (si ce sujet vous intéresse, nous vous recommandons la lecture de cette présentation de l’université de Stanford). C’est grâce à ces représentations vectorielles que fonctionnent les LLMs (ChatGPT et autres). Ces vecteurs vont encoder les différents aspects du langage et un modèle correctement entraîné peut donc “apprendre” les relations sémantiques entre les mots.
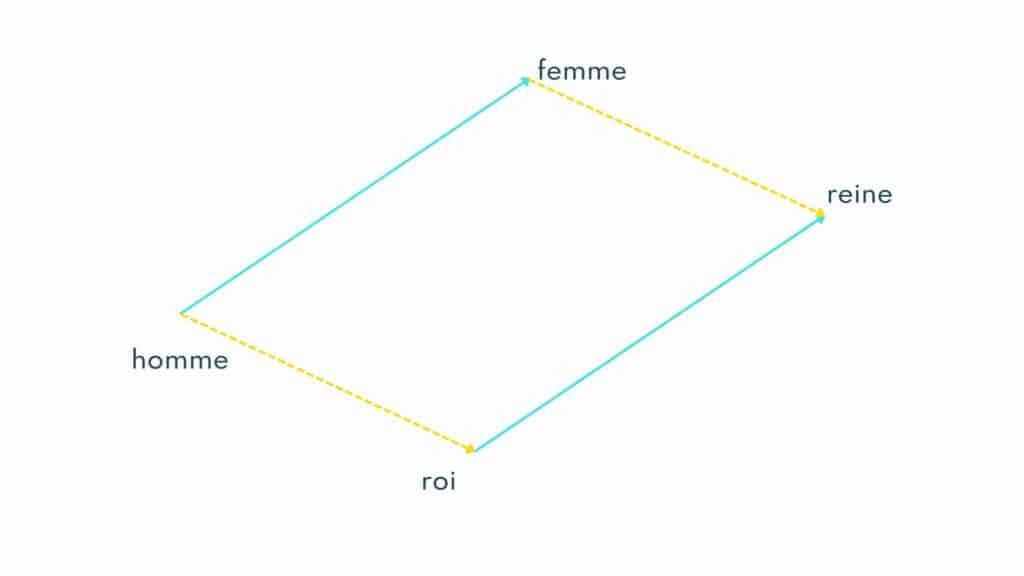
Illustration d’un exemple classique mettant en valeur la préservation de la sémantique dans l’espace vectoriel : v(roi) – v(homme) + v(femme) = v(reine)
Les avancées récentes sur les modèles d’IA sont directement applicables au matching produit
Les libellés produits sont de très bons candidats au prolongement lexical
- tous les produits ont un libellé (caisse ou ERP), ce qui permet un couverture complète des catalogues*.
- les principales caractéristiques sont souvent présente dans le libellé, ou le libellé enrichi des informations de nomenclature, ce qui permet une bonne discrimination des produits dans l’espace vectoriel résultant
L’encodage des libellés permet de représenter les différentes caractéristiques dans l’espace, et donc de détecter précisément les produits “proches” c’est-à-dire ayant les mêmes caractéristiques (ou presque : en pratique, les produits similaires ont les mêmes caractéristiques à l’exception de la marque, pour les produits de marque propre).
*Note sur la qualité des libellés : Le choix du type de libellé à utiliser dépend de plusieurs facteurs. Les libellés web sont souvent de meilleure qualité mais absents sur une partie du catalogue. Les libellés internes ont l’avantage d’être disponibles sur l’ensemble du catalogue mais de moins bonne qualité, avec de nombreuses abréviations pour pallier aux limites de caractères. Notre algorithme utilise une combinaison des différents types de libellés et permet une meilleure précision
Comment Mercio relève le défi du matching produit avec les derniers modèles d’IA
L’approche décrite ci-dessus est utilisée par Mercio pour générer algorithmiquement des recommandations de liens, avec un double objectif de démultiplier la productivité des utilisateurs et de fournir une vision détaillée du positionnement par rapport à la concurrence.
Les équipes techniques de Mercio ont relevé deux défis dans l’implémentation opérationnelle de l’algorithme :
- La sélection du bon modèle, ainsi que son entraînement et son paramétrage.
La révolution des LLM et les initiatives de mise à disposition de modèles déjà pré-entrainés ont réduit la barrière à l’entrée dans ce domaine. Une bonne compréhension du fonctionnement sous-jacent reste cependant nécessaire pour les réglages de fin.
- L’intégration de l’algorithme dans le cycle de vie des données de l’application.
Une approche naïve est d’entraîner et exécuter l’algorithme de manière indépendante de l’application. Cette approche mène souvent à une multiplication des échanges de données et une augmentation significative de la complexité et donc de la maintenance.
Les dernières technologies de data warehouse permettent d’exécuter ces algorithmes directement où les données sont stockées. La refonte complète de l’architecture de notre solution nous permet aujourd’hui de profiter pleinement de ces dernières révolutions.
Quelle est la place des équipes opérationnelles dans ce nouveau processus de matching produit ?
Des équipes opérationnelles augmentées
On observe que le développement de l’IA mène rarement à une suppression pure et simple de l’humain dans le processus, mais plutôt à une redistribution des rôles entre la machine et nous. C’est également le cas dans l’automatisation du matching produit, et cela permet de supprimer une charge de travail importante sur des tâches à faible valeur ajoutée et d’améliorer significativement la qualité et la couverture du matching.
Notre algorithme de rapprochement de produit paramétré et optimisé mène à des taux de validation de plus de 95%. Le pricer ou le category manager va pouvoir se concentrer sur les cas aux limites de manière efficace.
Dans le cas du matching, deux raisons font que l’humain restera utile :
- Les problèmes de données
Une donnée opérationnelle n’est jamais parfaite et des libellés incorrects ou incomplets, bien que rares, sont toujours possibles. - Le caractère intuitif de certains liens
En effet, alors que certains produits sont clairement comparables (mêmes caractéristiques), d’autres couples de produits peuvent faire l’objet de désaccord entre pricers ou acheteurs sur la comparabilité.
Par exemple, deux produits dont la différence de volume est très faible seront comparés par les clients (toutes autres caractéristiques identiques), mais si la différence de volume devient significative, alors ces produits seront trop éloignés pour être comparés. La définition de cette limite fait d’ailleurs l’objet de débats – parfois endiablés – entre les opérationnels.
On voit aussi d’autres raisons opérationnelles sur le contrôle du déploiement du chaînage : “Je chaîne cette catégorie progressivement, à mesure que je peux faire des investissements. Car si je chaîne tout immédiatement, mon indice va exploser et je vais me faire taper sur les doigts…” – un utilisateur anonyme 😉.
Comment assurer une bonne collaboration entre l’équipe et la machine ?
L’enjeu, dans cette coordination homme-machine, est de circonscrire précisément les périmètres de chaque partie (basé sur les forces et faiblesses de chacune). Et de réduire le nombre de clics au strict minimum dans l’interface applicative.
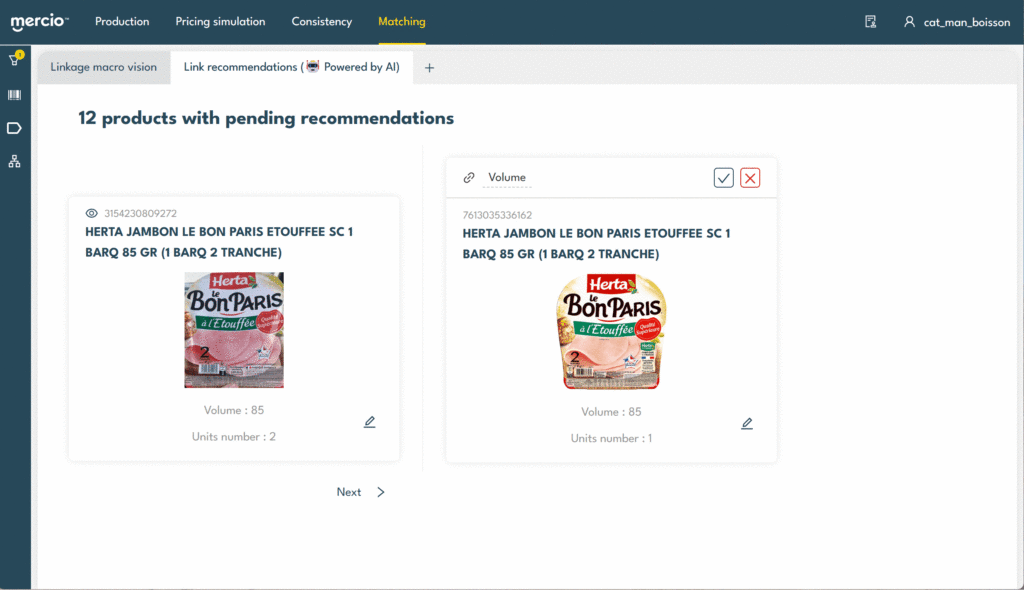
Un processus de revue optimisé pour les équipes opérationnelles
Une excellente précision dans les recommandations calculées et une expérience utilisateur optimisée permettent d’atteindre un rythme de création de 15 liens par minute, soit 900 liens par heure.
Et alors que la machine facilite le travail de l’humain en lui proposant des recommandations de liens, l’humain améliore la précision de l’algorithme en validant les propositions correctes. En effet, ces informations générées par la revue des liens sont ensuite utilisées pour entraîner l’algorithme sur des exemples concrets. Une collaboration parfaite, où l’humain et la machine s’enrichissent mutuellement.
Un chaînage complet et à jour est à la portée des plus gros catalogues du retail !
Conclusion : Une révolution pour le matching produit dans le retail
Le matching produit est une tâche complexe et chronophage, mais essentielle pour optimiser la gestion de l’assortiment, le pricing et l’image-prix des enseignes. Grâce aux avancées de l’intelligence artificielle, il est désormais possible d’automatiser une grande partie de ce processus, tout en laissant l’humain intervenir sur les cas les plus complexes.
Avec des algorithmes performants et une interface utilisateur optimisée, un matching complet et précis devient réalisable, même pour les catalogues les plus étendus. Les distributeurs qui adoptent ces outils se donnent les moyens d’améliorer leur compétitivité et leur performance, en gagnant en efficacité et en précision. Un processus maîtrisé, c’est un levier stratégique pour le retail !
Si la perception prix par les consommateurs vous intéresse, n’hésitez pas à lire notre article sur les biais cognitifs dans le pricing.
Et si vous voulez discuter pricing, technologies et algorithmes, contactez-moi !

