KI und Produkt-Matching: Mit Mercio die Produktivität um das 20-Fache steigern

Alexandre Point
March 17, 2025
Das Produkt-Matching oder Verkettung besteht darin, verschiedene, aber für den Verbraucher vergleichbare Artikel miteinander zu verknüpfen. Mit der zunehmenden Diversifizierung der Sortimente (Eigenmarken, Exklusivprodukte) ist dieser Prozess zeitaufwändig und äußerst mühsam geworden. Dennoch ist er unverzichtbar, um die Konkurrenz zu analysieren und Preise anzupassen. Semantische Analysen und KI ermöglichen es, diesen Prozess weitgehend zu automatisieren, während komplexe oder nicht standardisierte Fälle weiterhin manuell geprüft werden. Ein kombinierter Ansatz gewährleistet so ein präzises Matching, das entscheidend für ein effektives Preismanagement und eine starke Preiswahrnehmung ist. In diesem Artikel teilen wir unsere Erfahrungen mit den neuesten Entwicklungen auf diesem Gebiet.
Was bedeutet Produkt-Matching für einen Händler?
Das Verknüpfen verschiedener Produkte, die der Verbraucher als gleichwertig betrachtet
Produkt-Matching, auch als „horizontales Verkettung“ bekannt, beschreibt die Verknüpfung von zwei unterschiedlichen Produkten mit unterschiedlichen Produktschlüsseln, die aus Sicht des Endkunden vergleichbar sind.
Während einige Produkte in mehreren Geschäften desselben Marktes erhältlich sind (z. B. eine Flasche Coca-Cola oder ein Glas Nutella), finden sich andere nur in den Regalen einer einzigen Handelsgruppe.
Dies betrifft nicht nur Eigenmarkenprodukte, die spezifisch für jede Handelskette sind, sondern auch Markenprodukte, für die mit den Herstellern Exklusivverträge ausgehandelt wurden (z. B. Neuheiten oder spezielle Formate).

Die finanzielle Bedeutung ist erheblich: Produkte, die nicht exakt mit denen des übrigen Marktes identisch sind, machen je nach Händler einen großen Anteil des Umsatzes und einen noch größeren Anteil der Marge aus.
Die Dynamik geht in Richtung einer zunehmenden Entwicklung dieser Eigenheiten pro Händler, insbesondere durch die von vielen Handelsketten angekündigten Ziele zur Förderung von Eigenmarken (EM). Einzelhändler wie Lidl, Aldi oder Edeka haben eine starke Tradition im Bereich der Eigenmarken (EM). Insbesondere Discounter stützen sich auf ein sehr umfangreiches Eigenmarkensortiment, das oft mehr als 50 % ihres Angebots ausmacht. Diese Entwicklung erschwert die Vergleichbarkeit zwischen Händlern, wodurch mehr Spielraum für die Preisgestaltung und die Steuerung der Preiswahrnehmung entsteht.
Diese fehlende Vergleichbarkeit erschwert auch eine mögliche Preisangleichung der Wettbewerber. Beispielsweise geben nur wenige Händler die EAN-Codes ihrer Produkte auf ihren Websites an, um es den Mitbewerbern zu erschweren, eine relative Preispositionierung vorzunehmen.
In den letzten Jahren gab es ein regelrechtes Versteckspiel zwischen den Handelsketten, geprägt von EAN-Resets und dem Auslaufen von Exklusivverträgen. Das Ziel ist, für Verbraucher attraktive und sichtbare Preise anzubieten, die Wettbewerber nur schwer nachvollziehen können – um sie im Preiskampf zu überholen.
Eine umfassende und zuverlässige Basis von Verknüpfungen mit dem Markt ist aus mehreren Gründen von Nutzen
Für das Sortimentsmanagement ermöglicht diese Basis die Identifikation von „Lücken“ im Produktkatalog – sowohl im eigenen Katalog als auch bei der Konkurrenz – zur Weiterentwicklung oder Rationalisierung des Sortiments.
Für das Pricing ermöglicht sie die Preispositionierung Ihrer Produkte und die Überwachung Ihrer Preisposition (Berechnung Ihrer Preisindizes), da die Kunden diese Produkte miteinander vergleichen, die denselben Bedarf decken. Ohne eine Matching-Verknüpfung steuern Sie Ihr Pricing wie im Blindflug – und verlieren dabei den Überblick über einen erheblichen Teil Ihres Umsatzes.
Eine vollständige und aktuelle Liste von Matching-Verknüpfungen ist daher ein unverzichtbares Element für das Pricing eines Händlers!
Eine Matching-Verknüpfungsbasis einrichten und pflegen: leichter gesagt als getan!
Die Arbeitsbelastung für die Pricer oder Produktmanager ist enorm
Ein Hindernis für die Zuverlässigkeit des Produkt-Matchings ist die Arbeitsbelastung, die mit dem Matching verbunden ist. Ein nationaler Lebensmittelhändler verwaltet im Durchschnitt 8.000 bis 10.000 aktive Eigenmarkenreferenzen. Um diese mit 7 anderen Händlern abzugleichen, entsteht eine Datenbasis von über 50.000 Links. Diese Links müssen nicht nur erstellt, sondern kontinuierlich gepflegt werden, um Änderungen im Sortiment und neue Referenzen zu berücksichtigen. Diese Zahl ist eine niedrige Schätzung, da zu den Eigenmarken auch Exklusivprodukte hinzukommen, einige Bereiche noch größere Kataloge aufweisen (zum Beispiel im Do-it-yourself-Bereich) und regelmäßig neue Referenzen erscheinen (Neuheiten, EAN-Resets…).
Ein Matching-Prozess ohne Automatisierung führt zu einer zu hohen Arbeitsbelastung, selbst für die größten Teams. Umso mehr, als das Matching nur eine von vielen Aufgaben ist, unabhängig davon, welches Team dafür zuständig ist.
Die Heterogenität der Produkte und eine manchmal mangelhafte Datenqualität erschweren die Aufgabe
Die Vielfalt der Produkte in einem Händlerkatalog erhöht die Komplexität des Matching-Prozesses erheblich. Merkmale, die für den wahrgenommenen Wert eines Produkts entscheidend sind, variieren stark zwischen Kategorien.
Während beim Kauf von Deo das Fehlen von Aluminium ein wichtiges Kriterium ist, spielen bei Joghurt der Geschmack und bei Pasta die Kochzeit eine zentrale Rolle. Die Merkmale variieren also von einer Produktkategorie zur Anderen, und die Werte sind nicht standardisiert.
Eine umfassende und strukturierte Datenbank mit Produktmerkmalen ist nicht verfügbar und würde eine umfangreiche Kurationsarbeit für alle auf dem Markt erhältlichen Produkte erfordern (einschließlich Eigenmarken und Exklusivprodukte für das Matching).
Semantische Analyse: Eine bewährte Anwendung der KI
Die lexikalische Erweiterung hat in den letzten Jahren spektakuläre Entwicklungen erfahren
Die ersten Forschungsarbeiten zur mathematischen Erfassung der Komplexität der Sprache reichen bis in die 50er Jahre zurück, aber technologische Entwicklungen – insbesondere die Erhöhung der Rechen- und Speicherkapazitäten – sowie algorithmische Fortschritte haben in den letzten Jahren bedeutende Fortschritte ermöglicht.
Das sogenannte lexikalische Einbetten (englisch: word embeddings) wandelt Wörter oder Wortgruppen in mathematische Vektoren um, die verschiedene Aspekte der Sprache in einem mehrdimensionalen Raum abbilden. (Wenn Sie an diesem Thema interessiert sind, empfehlen wir Ihnen, diese Präsentation der Stanford University zu lesen). Dank dieser vektoriellen Darstellungen funktionieren die LLMs (wie ChatGPT und andere). Diese Vektoren kodieren verschiedene Aspekte der Sprache, und ein richtig trainiertes Modell kann daher die semantischen Beziehungen zwischen den Wörtern „lernen“.
v(König) - v(Mann) + v(Frau) = v(Königin)
Die jüngsten Fortschritte in der KI-Modellierung sind direkt auf das Produkt-Matching anwendbar
Produktbezeichnung sind sehr gute Kandidaten für die oben beschriebene lexikalische Erweiterung:
- Alle Produkte haben eine Bezeichnung (Kasse oder ERP), was eine vollständige Abdeckung der Kataloge ermöglicht.
- Die wichtigsten Merkmale sind oft in der Bezeichnung enthalten oder angereichert mit Nomenklaturinformationen, was eine gute Unterscheidung der Produkte im resultierenden Vektorraum ermöglicht.
Durch die Kodierung der Bezeichnungen ermöglicht es lassen sich Produkte mit ähnlichen Merkmalen präzise identifizieren. In der Praxis unterscheiden sich ähnliche Produkte häufig nur durch die Marke, insbesondere bei Eigenmarken.
*Hinweis zur Qualität der Bezeichnung: Webbezeichnung sind oft von besserer Qualität, jedoch fehlen sie bei einem Teil des Katalogs. Interne Bezeichner haben den Vorteil, dass sie im gesamten Katalog verfügbar sind, aber von geringerer Qualität sind, da viele Abkürzungen verwendet werden, um die Zeichenzahl zu begrenzen. Um die Auswirkungen einer schlechten Qualität der Bezeichner zu mindern, verwenden wir eine Kombination der verschiedenen Bezeichnungstypen, um die Genauigkeit unseres Algorithmus zu verbessern.
Wie Mercio die Herausforderung des Produkt-Matchings mit den neuesten KI-Modellen meistert
Mercio setzt diesen Ansatz ein, um mit Algorithmen präzise Verknüpfungsempfehlungen zu generieren. Ziel ist es, die Produktivität der Nutzer deutlich zu steigern und eine umfassende Übersicht zur Marktposition im Wettbewerbsvergleich zu schaffen.
Die technischen Teams von Mercio haben zwei Herausforderungen bei der operativen Umsetzung des Algorithmus gemeistert:
- Die Auswahl des richtigen Modells sowie dessen Training und Parametrierung.
Die Revolution der LLMs und die Initiativen zur Bereitstellung bereits vortrainierter Modelle haben die Einstiegshürde in diesem Bereich verringert. Ein gutes Verständnis der zugrunde liegenden Funktionsweise bleibt jedoch notwendig für die Feinabstimmung.
- Die Integration des Algorithmus in den Lebenszyklus der Anwendungsdaten.
Ein naiver Ansatz wäre es, den Algorithmus unabhängig von der Anwendung zu trainieren und auszuführen. Dieser Ansatz führt oft zu einer Vermehrung von Datenaustauschen und einer signifikanten Erhöhung der Komplexität und damit der Wartung. Die neuesten Technologien von Data Warehouses ermöglichen es, diese Algorithmen direkt dort auszuführen, wo die Daten gespeichert sind. Die vollständige Neugestaltung der Architektur unserer Lösung ermöglicht es uns heute, diese neuesten Revolutionen voll auszuschöpfen.
Welche Rolle spielen die betrieblichen Teams in diesem neuen Produkt-Matching-Prozess?
Erweiterte betriebliche Teams
KI ersetzt in den seltensten Fällen vollständig den Menschen. Stattdessen ermöglicht sie eine neue Rollenverteilung, bei der sich operative Teams auf wertschöpfende Aufgaben konzentrieren können. Beim Produkt-Matching reduziert KI die Arbeitsbelastung deutlich und verbessert gleichzeitig die Qualität und Abdeckung.
Unser parametrierter und optimierter Produkt-Matching-Algorithmus führt zu Validierungsraten von über 95 %. Der Pricer oder Category Manager kann sich effizient auf die Grenzfälle konzentrieren.
Im Fall des Matchings gibt es zwei Gründe, warum der Mensch weiterhin nützlich bleiben wird:
- Datenprobleme
Operative Daten sind nie perfekt, und fehlerhafte oder unvollständige Bezeichnungen, obwohl selten, sind immer möglich. - Die Intuitivität bestimmter Verknüpfungen
Während einige Produkte eindeutig vergleichbar sind (gleiche Merkmale), können bei anderen Produktpaaren Unstimmigkeiten zwischen Pricers oder Einkäufern über die Vergleichbarkeit auftreten. Ein Beispiel: Produkte mit minimalen Volumenunterschieden (bei sonst identischen Merkmalen) werden von Kunden oft verglichen. Werden die Volumenunterschiede jedoch signifikant, sind sie für den Vergleich weniger geeignet. Diese Schwelle ist ein häufiger Diskussionspunkt – manchmal sogar hitzig – unter den beteiligten Teams.
Es gibt auch andere operative Gründe für die Kontrolle der Implementierung des Matchings: "Ich werde diese Kategorie schrittweise verknüpfen, während ich Investitionen tätigen kann. Denn wenn ich alles sofort verknüpfe, wird mein Index explodieren und ich werde dafür kritisiert..." – ein anonymer Nutzer 😉.
Wie gewährleistet man eine gute Zusammenarbeit zwischen dem Team und der Maschine?
Das Ziel bei dieser Mensch-Maschine-Koordination besteht darin, die Bereiche jeder Partei genau abzugrenzen (basierend auf den Stärken und Schwächen jeder Seite). Und die Anzahl der Klicks in der Anwendungsoberfläche auf das notwendige Minimum zu reduzieren.
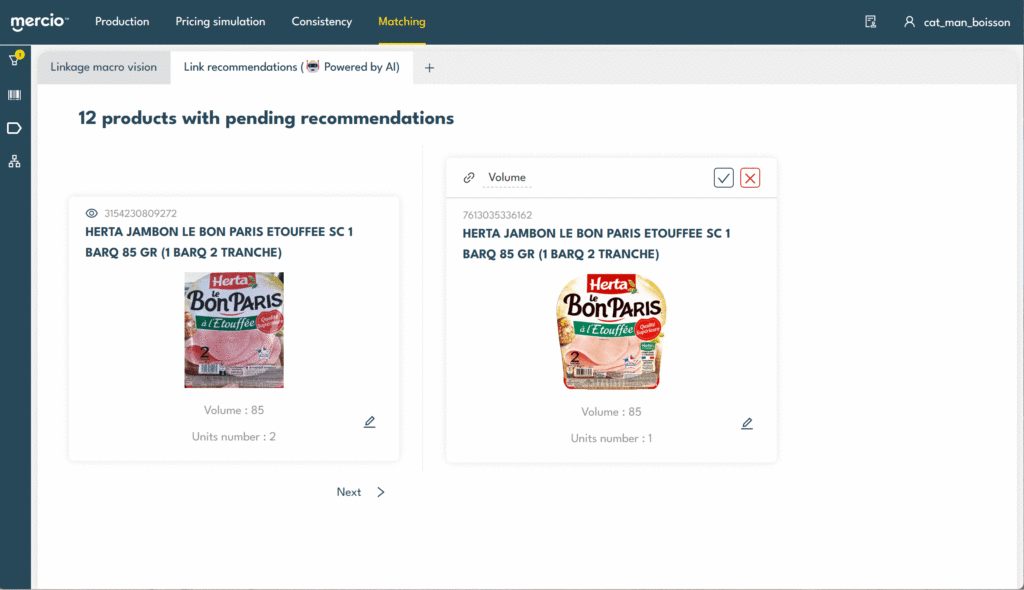
Eine exzellente Präzision in den berechneten Empfehlungen und eine optimierte Benutzererfahrung ermöglichen eine Erstellungsgeschwindigkeit von 15 Links pro Minute, also 900 Links pro Stunde.
Und während die Maschine dem Menschen die Arbeit erleichtert, indem sie ihm Link-Empfehlungen vorschlägt, verbessert der Mensch die Präzision des Algorithmus, indem er die richtigen Vorschläge validiert. Diese durch die Link-Überprüfung gewonnenen Informationen werden dann verwendet, um den Algorithmus mit konkreten Beispielen zu trainieren. Eine perfekte Zusammenarbeit, bei der sich Mensch und Maschine gegenseitig bereichern.
Ein vollständiges und aktuelles Matching ist auch für die größten Kataloge im Einzelhandel erreichbar!
Fazit: Eine Revolution für das Produkt-Matching im Einzelhandel
Das Produkt-Matching ist eine komplexe und zeitaufwändige Aufgabe, die jedoch entscheidend ist, um das Sortiment, die Preisgestaltung und das Preisimage der Einzelhändler zu optimieren. Dank der Fortschritte in der künstlichen Intelligenz ist es nun möglich, einen Großteil dieses Prozesses zu automatisieren, wobei der Mensch bei den komplexesten Fällen weiterhin eingreifen kann.
Mit leistungsstarken Algorithmen und einer optimierten Benutzeroberfläche wird ein vollständiges und präzises Matching auch für die umfangreichsten Kataloge realisierbar. Einzelhändler, die diese Tools einsetzen, verbessern ihre Wettbewerbsfähigkeit und Leistung, indem sie in Effizienz und Präzision gewinnen.
Ein effizient gesteuerter Matching-Prozess wird zum entscheidenden Wettbewerbsvorteil für den Einzelhandel! Wenn Sie an der Preiswahrnehmung der Verbraucher interessiert sind, lesen Sie unbedingt unseren Artikel über kognitive Verzerrungen im Pricing.
Und wenn Sie über Pricing, Technologien und Algorithmen sprechen möchten, kontaktieren Sie mich gerne!
Alexandre Point
Alexandre leitet unsere Entwicklungsteams und stellt sicher, dass Mercio der innovativste Editor für das Pricing im Großhandelsvertrieb bleibt. Als Absolvent der Ecole Polytechnique und der Stanford University sowie als erfahrener Unternehmer verfügt er sowohl über einen exzellenten Unternehmergeist als auch über eine unstillbare Neugier, die es uns ermöglicht, bei der Innovation für unsere Einzelhandelskunden noch weiterzugehen.


